R est un langage de programmation extrêmement puissant et polyvalent pour la data science. Grâce à sa vaste gamme de packages, R offre un écosystème étendu qui permet une manipulation efficace des données, la visualisation, la modélisation statistique, l’apprentissage automatique, et bien plus encore. Dans cet article, nous explorerons les 15 principaux packages R que tout data scientist devrait connaître. Que vous débutiez votre parcours en data science ou que vous cherchiez à élargir votre boîte à outils, ces packages sont essentiels pour effectuer des analyses avancées et obtenir des informations précieuses à partir de vos données.
1. dplyr
dplyr est la pierre angulaire de la manipulation de données en R. Avec des fonctions comme filter(), select(), mutate(), et summarize(), ce package simplifie les tâches complexes de traitement des données en un code clair et lisible. Il est optimisé pour la rapidité et la facilité d’utilisation, ce qui en fait un outil fondamental pour le sous-ensemble, la transformation et la synthèse des dataframes.
2. ggplot2
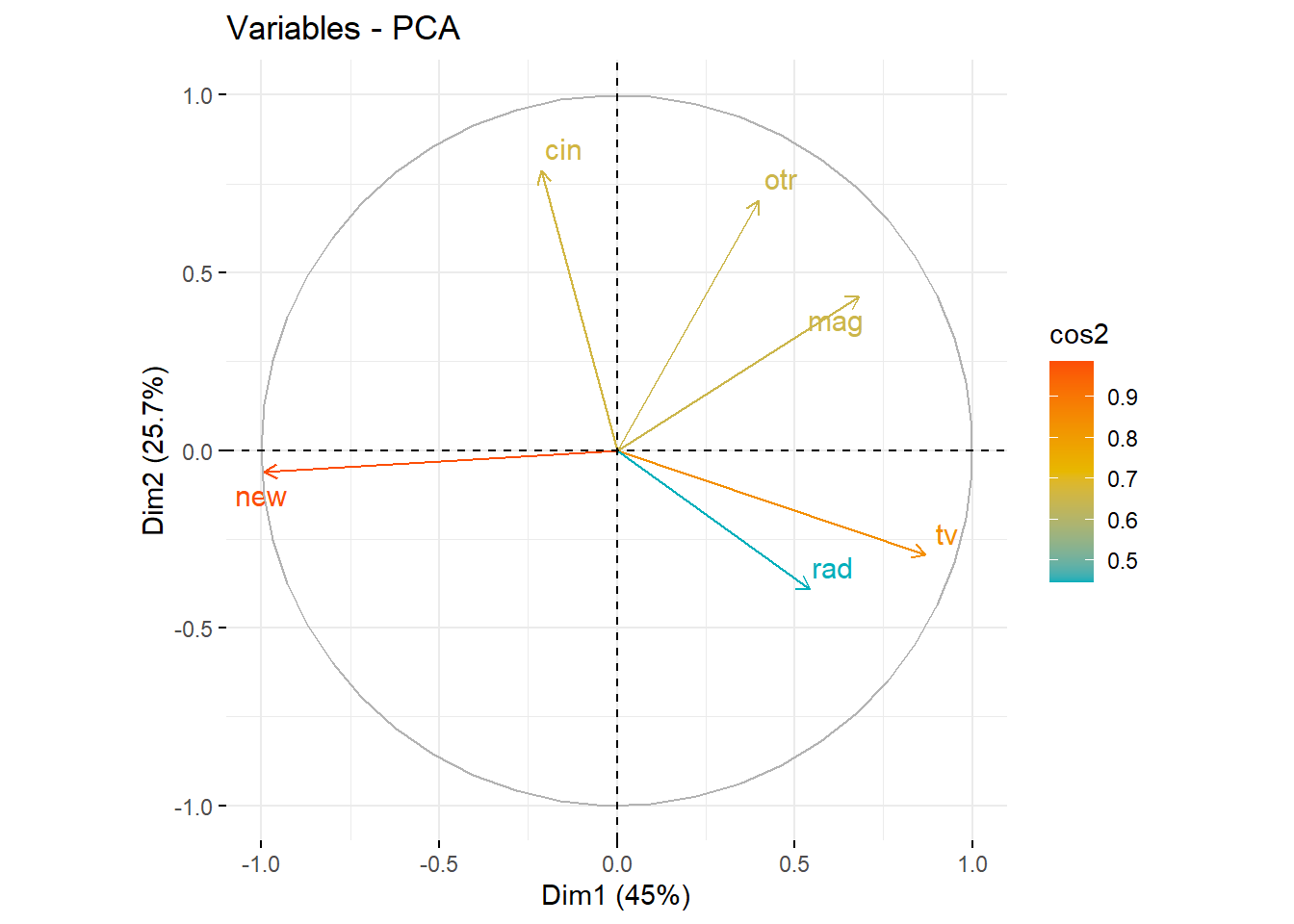
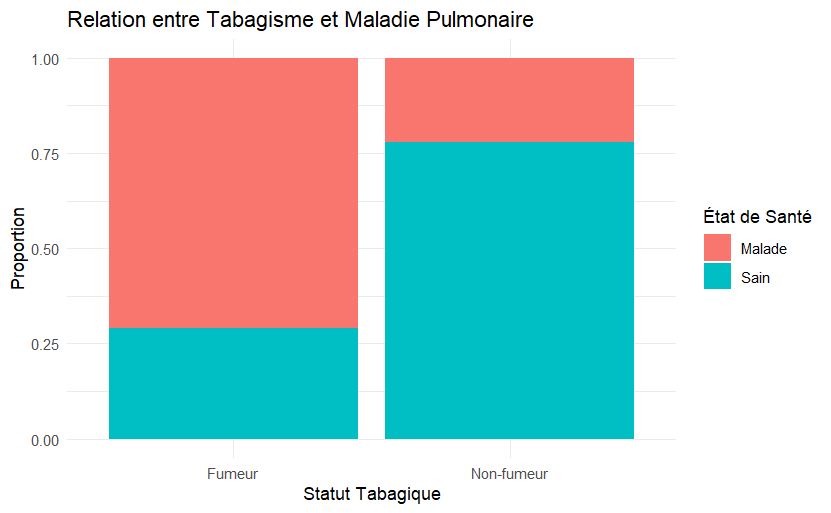
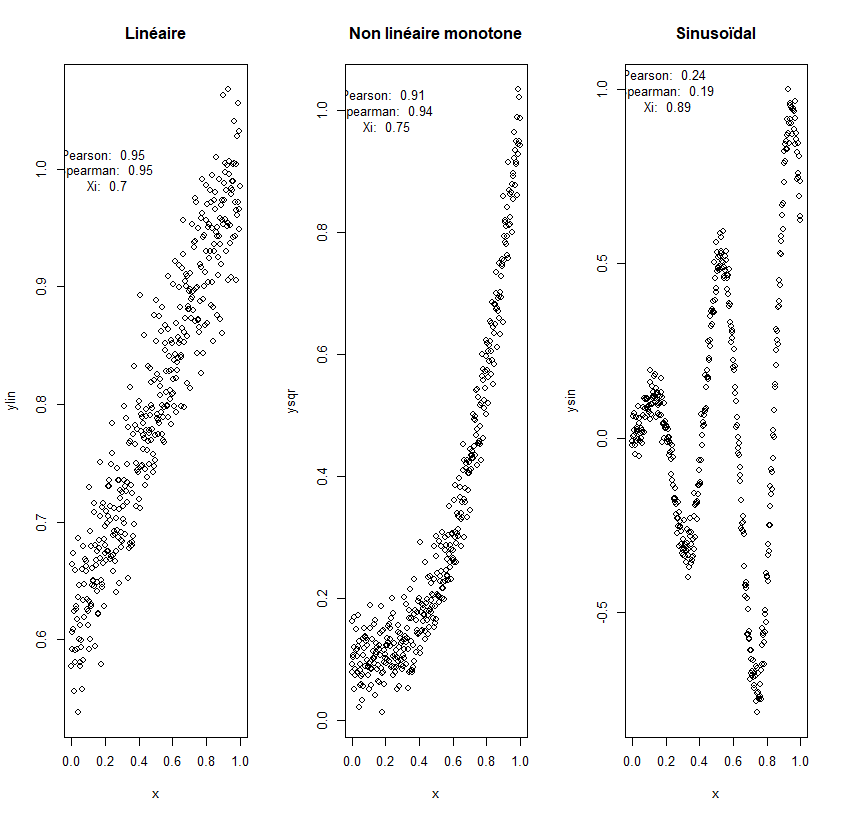
En matière de visualisation de données, ggplot2 est le package incontournable. Basé sur la grammaire des graphiques, il vous permet de créer des visualisations impressionnantes et complexes avec seulement quelques lignes de code. Que vous ayez besoin de faire de simples nuages de points ou des visualisations élaborées à plusieurs couches, ggplot2 offre une flexibilité et un contrôle esthétique inégalés.
3. igraph
igraph est un package puissant pour l’analyse et la visualisation de réseaux en R. Il offre une large gamme de fonctionnalités pour travailler avec des graphes, allant de la création et manipulation de structures de graphes à l’analyse de réseaux complexes. Avec igraph, vous pouvez facilement calculer des mesures de centralité, identifier des communautés, visualiser des réseaux de manière interactive et appliquer divers algorithmes de théorie des graphes. Ce package est particulièrement utile pour les data scientists travaillant sur des problèmes impliquant des relations entre entités, tels que l’analyse de réseaux sociaux, l’étude des interactions protéine-protéine en bioinformatique, ou la modélisation de systèmes complexes en économie et en sciences sociales. La flexibilité d’igraph et sa capacité à gérer efficacement de grands réseaux en font un outil essentiel pour toute analyse basée sur les graphes en data science.
4. caret
Pour les tâches d’apprentissage automatique, caret (Classification And REgression Training) est indispensable. Il fournit une interface unifiée pour construire et évaluer des modèles prédictifs, offrant des outils pour la sélection de caractéristiques, l’entraînement de modèles et l’ajustement des hyperparamètres. Caret simplifie le flux de travail d’apprentissage automatique, facilitant l’application d’algorithmes à vos données.
5. randomForest
randomForest est un package populaire pour l’apprentissage d’ensemble et la construction de modèles basés sur les arbres de décision. En combinant les prédictions de plusieurs arbres de décision, il fournit des prédictions robustes et précises, particulièrement utiles pour les problèmes de classification et de régression. C’est un choix privilégié pour travailler avec des ensembles de données de grande dimension.
6. lubridate
La gestion des dates et des heures en R peut être délicate, mais lubridate la rend beaucoup plus facile. Ce package fournit des fonctions intuitives pour analyser, manipuler et formater les données de date et d’heure, vous permettant d’extraire des composants, de calculer des différences et de gérer les fuseaux horaires sans effort. Lubridate est essentiel pour toute analyse impliquant des données temporelles.
7. stringr
Les données textuelles sont de plus en plus importantes en data science, et stringr est le package pour la manipulation de chaînes de caractères et l’extraction de texte. Il offre une interface cohérente et conviviale pour manipuler les chaînes, y compris la correspondance de motifs, l’extraction et le remplacement. Stringr est particulièrement utile lorsqu’il s’agit de données textuelles non structurées ou d’analyse de texte.
8. data.table
data.table est un package haute performance pour la manipulation de données. Il est conçu pour gérer efficacement de grands ensembles de données, offrant une syntaxe similaire aux dataframes mais avec un traitement plus rapide. Data.table excelle dans le filtrage, l’agrégation et la jointure de données, ce qui en fait un outil puissant pour les tâches de big data.
9. Prophet
Pour la prévision de séries temporelles, Prophet est un package incontournable. Développé par Facebook, il vous permet de modéliser des données de séries temporelles complexes avec des effets de saisonnalité et de jours fériés. Prophet est particulièrement bon pour gérer les données manquantes et les changements brusques de tendances, ce qui le rend idéal pour les prévisions commerciales et l’analyse financière.
10. rvest
rvest est le package de référence pour le web scraping en R. Il simplifie le processus d’extraction de données à partir de pages web en fournissant des outils pour lire le HTML, naviguer dans le DOM et extraire les informations dont vous avez besoin. Rvest est parfait pour collecter des données à partir de sources en ligne, que ce soit pour la recherche, l’analyse de marché ou l’intelligence concurrentielle.
11. shiny
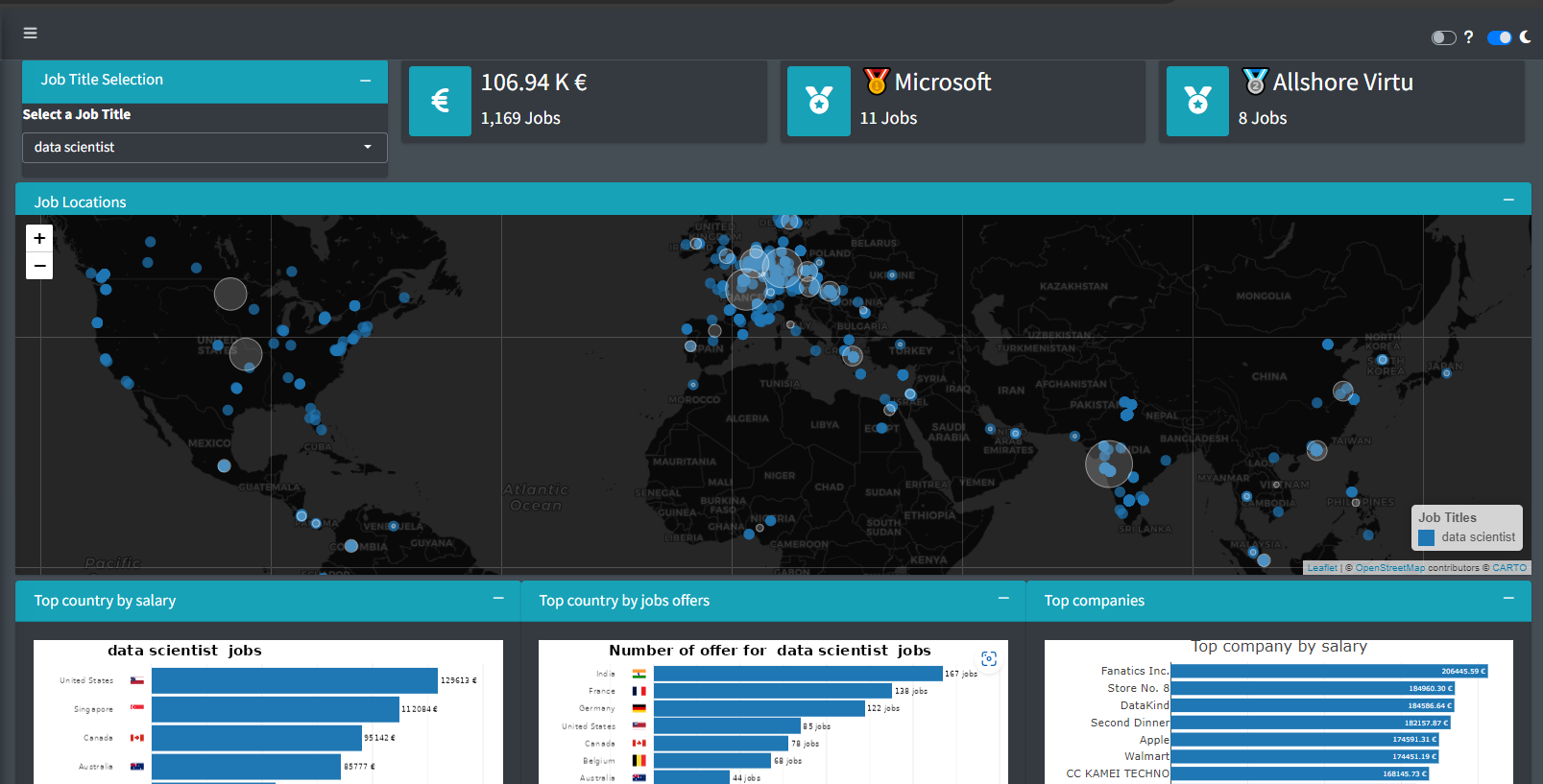
shiny vous permet de créer des applications web interactives directement à partir de R. Avec Shiny, vous pouvez construire des tableaux de bord interactifs, des visualisations et des outils personnalisés sans connaissances approfondies en développement web. Ce package est parfait pour partager vos résultats de data science de manière engageante et accessible.
12. jsonlite
Comme les données sont souvent au format JSON, jsonlite est un package essentiel pour analyser et générer du JSON en R. Il vous permet de convertir des données JSON en objets R et vice versa, facilitant le travail avec les API et les services web qui fournissent du JSON. Jsonlite est particulièrement utile pour intégrer R avec des applications web.
13. tidymodels
tidymodels est une collection de packages conçus pour rationaliser le processus d’apprentissage automatique en R. Il comprend des outils pour le prétraitement des données (recipes), la spécification des modèles (parsnip) et l’évaluation des modèles (yardstick). Tidymodels offre un flux de travail ordonné et cohérent pour la construction de pipelines d’apprentissage automatique.
14. parallel
parallel est un package essentiel pour tirer parti du traitement multi-cœur en R. Il vous permet d’exécuter des calculs simultanément sur plusieurs processeurs, accélérant considérablement des tâches comme les simulations et l’analyse de données à grande échelle. Parallel est particulièrement utile pour optimiser les performances dans les tâches gourmandes en calcul.
15. RSQLite
RSQLite fournit une interface aux bases de données SQLite, un moteur de base de données léger et autonome. Ce package est idéal pour gérer des bases de données locales en R, offrant un moyen simple de gérer, interroger et mettre à jour vos données. Il est particulièrement utile pour les projets qui nécessitent des solutions de base de données portables et efficaces sans la surcharge d’un système de base de données complet.
Conclusion
Ces 15 packages R couvrent les outils essentiels nécessaires pour la manipulation de données, la visualisation, l’apprentissage automatique, l’analyse de séries temporelles, l’extraction de texte, l’analyse de réseaux, et bien plus encore. En incorporant ces packages dans votre flux de travail, vous serez équipé pour relever un large éventail de défis en data science, du nettoyage et de l’exploration des données à la construction de modèles prédictifs, l’analyse de réseaux complexes et la communication de vos résultats. Que vous soyez un data scientist confirmé ou débutant, maîtriser ces packages améliorera considérablement votre productivité et votre efficacité en R.
Vous pourrez aimer