La statistique descriptive est une étape fondamentale de l’analyse de données qui vise à résumer et à présenter les caractéristiques clés d’un ensemble de données. Elle joue un rôle crucial dans la compréhension préliminaire de vos données avant de plonger dans des analyses plus avancées, la modélisation. C’est l’examen approfondi de chaque caractère mesuré ou enregistré dans votre ensemble de données. Dans cet article, nous explorerons les différentes étapes pour décrire une variable de manière significative et informative.
Une approche essentielle dans cette description est d’adapter les indicateurs en fonction du type de variable que vous manipulez. Les différentes types de variables (quantitatives, catégoriques, ordinales, etc.) exigent des paramètres spécifiques pour extraire des informations pertinentes.
Types de variables
Il est essentiel de comprendre les différents types de variables, car cela influence la manière dont nous les traitons et les analysons. Les types de variables se divisent généralement en deux catégories principales : les variables quantitatives et les variables qualitatives.
Variables Quantitatives
Les variables quantitatives sont des variables qui représentent des quantités mesurables et sont exprimées numériquement. Elles peuvent être classées en deux sous-catégories : les variables quantitatives discrètes et les variables quantitatives continues.
Variables Quantitatives Discrètes : Ce sont des variables numériques qui prennent des valeurs distinctes et dénombrables. Par exemple, le nombre de voitures dans un parking est une variable discrète, car il ne peut s’agir que d’un nombre entier, comme 1, 2, 3, etc.
Variables Quantitatives Continues : Ce sont des variables numériques qui peuvent prendre n’importe quelle valeur dans une plage continue. Par exemple, la hauteur des individus peut varier de 150 cm à 180 cm, et elle est considérée comme une variable quantitative continue.
Variables Qualitatives
Les variables qualitatives représentent des catégories, des qualités ou des caractéristiques plutôt que des quantités mesurables. Elles peuvent être classées en trois sous-catégories : les variables qualitatives nominales, ordinales et binaires.
Variables Qualitatives Nominatives : Ce sont des variables qui représentent des catégories sans ordre particulier. Par exemple, la couleur des yeux (bleu, vert, marron) est une variable nominale.
Variables Qualitatives Ordinales : Ce sont des variables qui représentent des catégories avec un ordre ou un classement. Par exemple, le niveau de satisfaction (faible, moyen, élevé) est une variable ordinale.
Variables Qualitatives Binaires : Ce sont des variables qui ont seulement deux catégories possibles, souvent représentées par 0 et 1. Par exemple, le statut du paiement (payé/non payé) est une variable binaire.
Paramètres de description
Les paramètres de description jouent un rôle essentiel pour comprendre et résumer des ensembles de données. Ces paramètres permettent de comprendre à la fois où se situe le cœur des données (tendance centrale) et comment les données sont dispersées autour de cette tendance centrale (dispersion). Les mesures de tendance centrale et de dispersion sont essentielles pour obtenir une vision complète de la structure des données.
Mesures de Tendance Centrale
Les mesures de tendance centrale sont utilisées pour déterminer la valeur “typique” ou “moyenne” d’un ensemble de données. Les trois mesures de tendance centrale les plus couramment utilisées sont la moyenne, la médiane et le mode.
La Moyenne : La moyenne, également connue sous le nom de moyenne arithmétique, est l’un des paramètres de description les plus simples et les plus couramment utilisés. Elle se calcule en additionnant toutes les valeurs d’un ensemble de données et en les divisant par le nombre total de valeurs. La moyenne donne une idée de la valeur centrale de la distribution des données. Cependant, elle peut être sensible aux valeurs extrêmes, ce qui signifie qu’une seule valeur aberrante peut considérablement influencer la moyenne.
La Médiane : La médiane est un autre paramètre de description de la tendance centrale. Contrairement à la moyenne, la médiane n’est pas affectée par les valeurs extrêmes. Pour calculer la médiane, il suffit de trier toutes les valeurs de l’ensemble de données et de sélectionner la valeur du milieu. Si le nombre de valeurs est pair, la médiane est la moyenne des deux valeurs centrales.
Le Mode : Le mode est la valeur qui apparaît le plus fréquemment dans un ensemble de données. Il peut y avoir un mode (distribution unimodale) ou plusieurs modes (distribution multimodale). Le mode est utile pour identifier les valeurs les plus courantes dans un ensemble de données.
Mesures de Dispersion
Les mesures de dispersion nous informent sur l’écart ou la variation des valeurs dans un ensemble de données. Elles comprennent l’écart type, l’écart interquartile (IQR) et la plage.
L’Écart Type : L’écart type est un paramètre de description qui mesure la dispersion ou la variabilité des données par rapport à la moyenne. Plus l’écart type est élevé, plus les données sont dispersées autour de la moyenne. Il se calcule en prenant la racine carrée de la variance, qui est la moyenne des carrés des écarts entre chaque valeur et la moyenne.
Les Quartiles : Les quartiles divisent la distribution des données en quatre parties égales. Le premier quartile (Q1) représente le 25e percentile, la médiane (Q2) est le 50e percentile, et le troisième quartile (Q3) est le 75e percentile. Les quartiles sont utiles pour comprendre la répartition des données et pour détecter la présence de valeurs aberrantes. L’écart interquartile (IQR) est la différence entre le troisième quartile (Q3) et le premier quartile (Q1).
La plage ou l’étendue : La plage est simplement la différence entre la valeur maximale et la valeur minimale dans l’ensemble de données. Elle donne une idée de la variation totale des données.
La Proportion
La proportion est une mesure relative qui représente la part ou la contribution d’une catégorie ou d’un événement par rapport au total. Elle s’exprime généralement sous la forme d’un pourcentage. Les proportions sont essentielles pour comprendre la composition d’un groupe par rapport à un tout.
Description d’une variable quantitative
L’analyse d’une variable quantitative demande une attention particulière, car elle permet de comprendre la distribution, la tendance centrale et la dispersion des valeurs.
Moyenne et Écart-type vs Médiane et Quartiles
Lorsque vous travaillez avec une variable quantitative, vous avez le choix entre deux approches principales pour la description statistique : l’utilisation du couple moyenne et écart-type ou du couple médiane et quartiles. Le choix entre ces deux approches dépend de la distribution des données et de l’objectif de votre analyse.
L’histogramme est l’un des outils les plus puissants pour visualiser la distribution d’une variable quantitative. Il regroupe les valeurs en intervalles appelés “classes” et affiche la fréquence de chaque classe sous forme de barres. L’examen de la forme de l’histogramme permet de déterminer si la distribution est symétrique, bimodale, uniforme ou autre.
Moyenne et Écart-type : Cette approche est appropriée lorsque les données suivent approximativement une distribution normale, que la moyenne est une mesure adéquate du centre des données, que vous souhaitez quantifier la variabilité des données ou que vous êtes intéressé par des valeurs spécifiques et leur distance par rapport à la moyenne.
Médiane et Quartiles : Cette approche est privilégiée lorsque les données présentent une distribution asymétrique ou non normale, qu’elles contiennent des valeurs aberrantes, que vous voulez une mesure de la tendance centrale robuste aux valeurs extrêmes ou que vous êtes plus intéressé par la répartition des valeurs qu’une valeur centrale unique.
Le choix entre ces deux approches dépend de la distribution des données et de vos objectifs d’analyse. Il est souvent judicieux d’examiner les deux approches pour obtenir une compréhension complète de vos données, en mettant en évidence les caractéristiques centrales et de dispersion.
Description d’une variable qualitative
Répartition des Catégories
L’une des premières étapes de la statistique descriptive pour une variable qualitative consiste à examiner la répartition des catégories. Pour chaque catégorie, nous pouvons calculer le nombre d’occurrences (fréquence) et la proportion par rapport au total. Par exemple, si nous étudions la variable “Statut Matrimonial” d’un échantillon, nous pouvons déterminer combien de personnes sont mariées, célibataires, divorcées, etc., et exprimer ces chiffres en pourcentage.
Visualisation
La visualisation des données est un moyen puissant de présenter la répartition des catégories d’une variable qualitative. Les diagrammes en barres, les camemberts (ou diagrammes circulaires) et les diagrammes en secteurs sont couramment utilisés pour représenter visuellement la distribution des catégories. Ces graphiques permettent une compréhension rapide de la structure des données.
Application
Pour la réalisation de ce travail nous allons utiliser des données simulées qui peuvent être téléchargées . Si vous rencontrez des difficultés lors de l’importation de fichiers dans R, n’hésitez pas à consulter notre article dédié à ce sujet. Vous trouverez aussi ici des informations précieuses pour structurer efficacement vos fichiers et dossiers.
# Importation à partir d'un fichier CSVstat_descr_data <-read.csv("data/stat_descr_data.csv", sep =";")head(stat_descr_data) # visualiser les premières lignes des données.
Age : Cette variable représente l’âge des individus dans l’échantillon.
Revenu : Il s’agit du revenu en dollars des individus.
Score : Cette variable représente un score qui peut varier entre 0 et 100.
Depenses : Il s’agit des dépenses des individus.
Statut Matrimonial : Cette variable qualitative représente le statut matrimonial des individus
Variable Quantitative, distribution normale
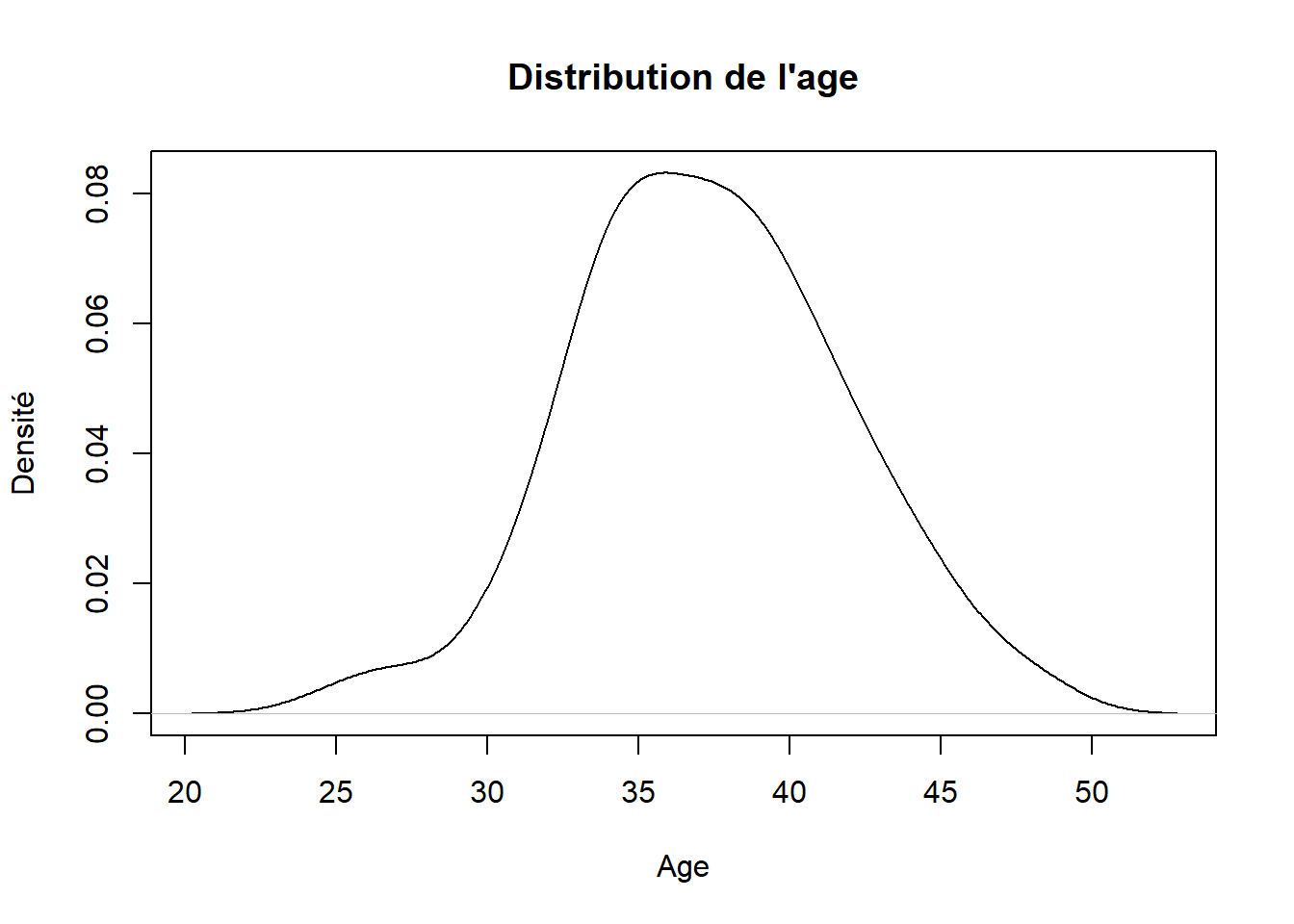
curve_normale <-density(stat_descr_data$Age)# Tracé de la courbe de densitéplot(curve_normale, main ="Distribution de l'age", xlab ="Age", ylab ="Densité")
La courbe de densité présentée ici offre une vue détaillée de la distribution de l’age des individus. Les valeurs s’étendent symétriquement de part et d’autre de la moyenne, montrant ainsi une distribution normale bien équilibrée. Elles varient entre 25 ans et 48 ans , avec une moyenne de 37 ± 4 ans.
Variable Quantitative, distribution non normale
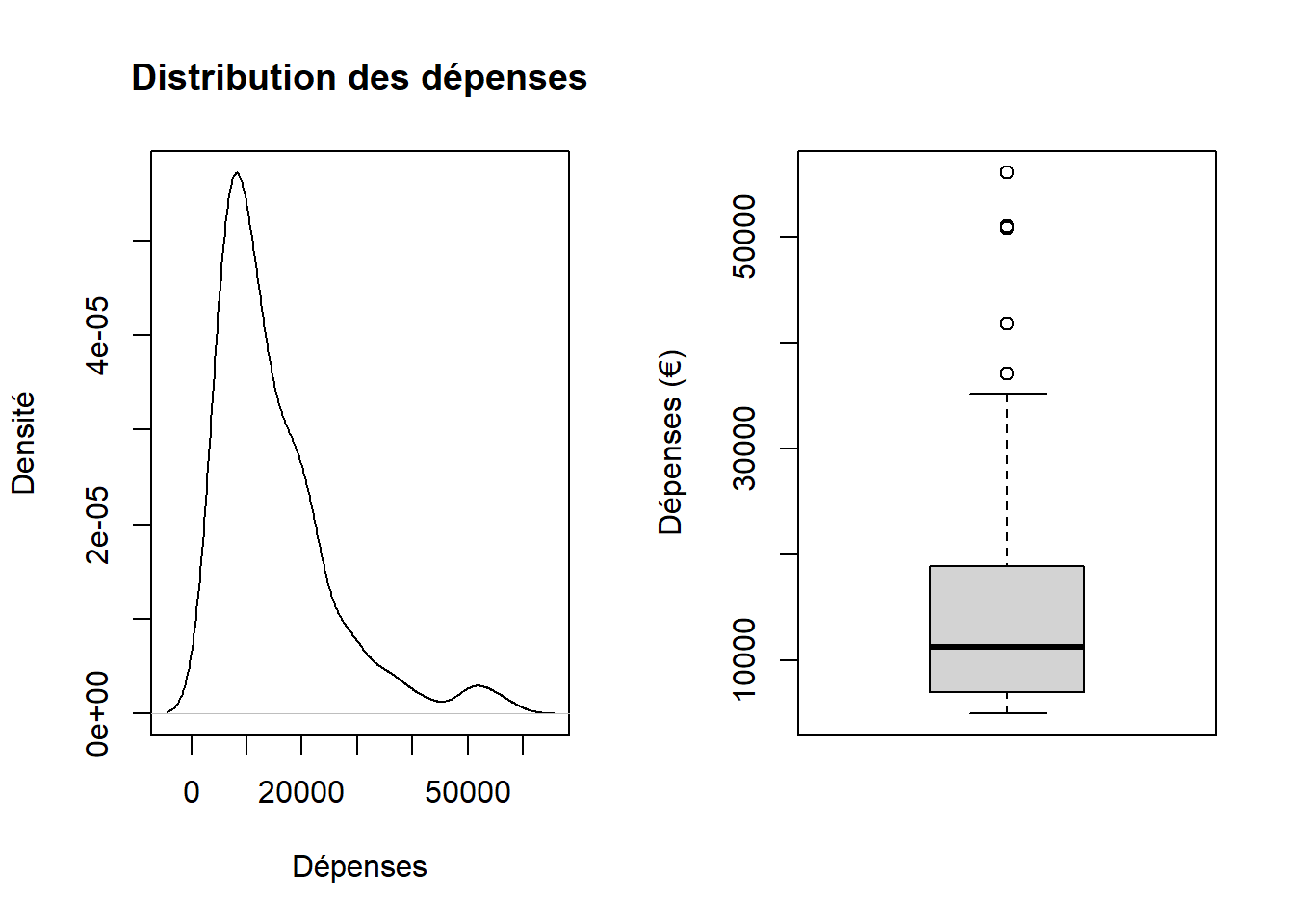
curve_normale <-density(stat_descr_data$Depenses)# Tracé de la courbe de densitépar(mfrow =c(1,2))plot(curve_normale, main ="Distribution des dépenses", xlab ="Dépenses", ylab ="Densité")boxplot(stat_descr_data$Depenses, ylab ="Dépenses (€)")
La courbe de densité présentée ici offre une vue détaillée de la distribution des dépenses des individus. Les données suivent une distribution non normale. Les valeurs varient entre 5030 € et 56016 € avec une médiane de 11340 € [7087 ; 18917.25] €. Cette distribution est asymétrique, avec une queue longue du côté droit, indiquant que la plupart des individus ont des dépenses relativement faibles, tandis que quelques-uns ont des dépenses considérablement plus élevées.
Variable Qualitative : Statut Matrimonial
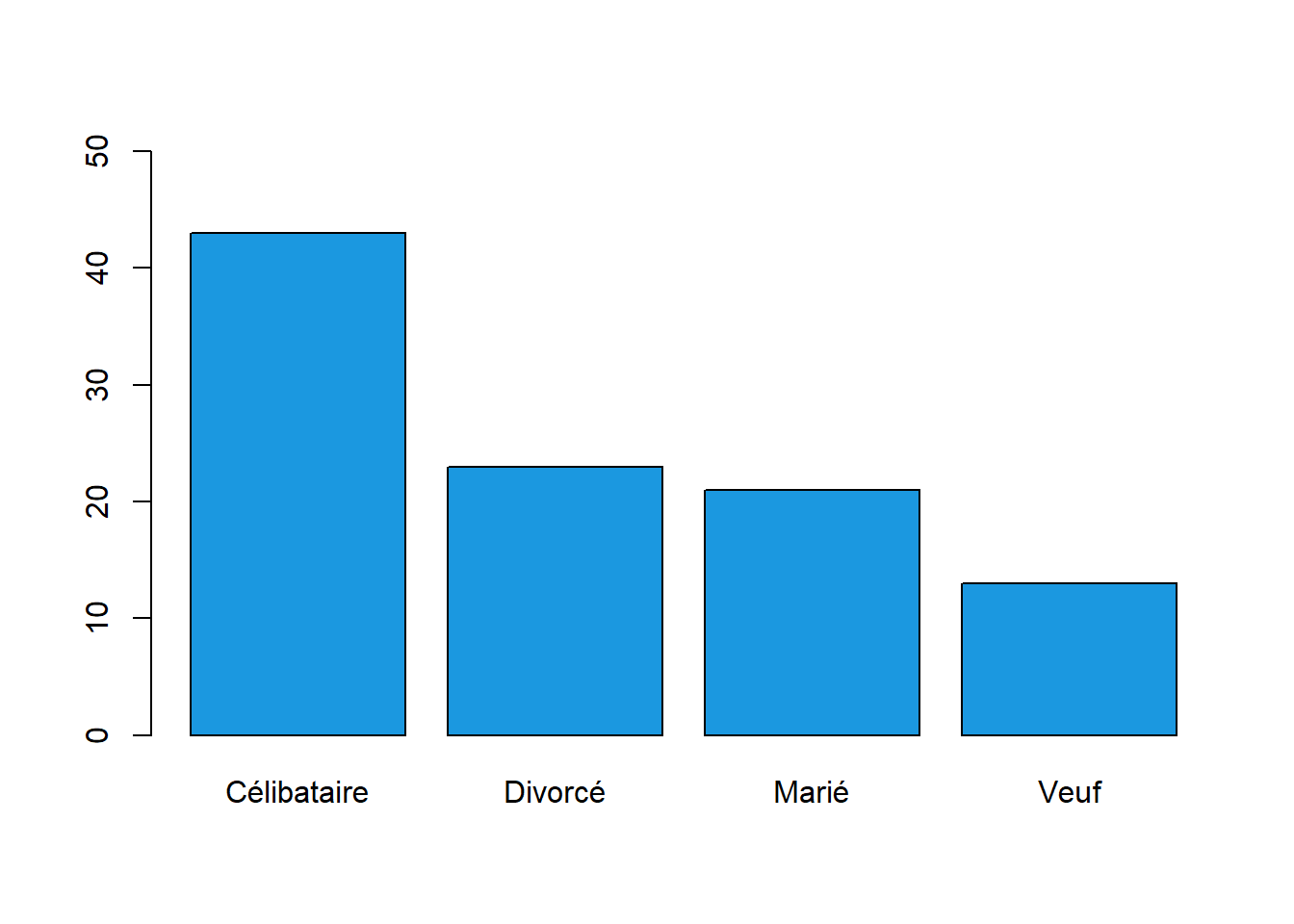
barplot(prop.table(table(stat_descr_data$Statut.Matrimonial))*100, col ="#1b98e0", ylim =c(0,50))
La variable Statut Matrimonial représente l’état civil des individus dans notre échantillon. Cette variable est importante pour comprendre la composition de notre population d’étude et peut fournir des informations précieuses sur les caractéristiques sociales de notre groupe.
Parmi les individus de notre échantillon, nous observons plusieurs modalités pour le statut matrimonial. Celles-ci comprennent Célibataire, Marié, Divorcé, Veuf. Chaque modalité représente un état matrimonial spécifique. La répartition des individus parmi ces modalités donne un aperçu de la diversité des situations matrimoniales au sein de notre échantillon. Nous pouvons constater que 43 % de nos sujets sont célibataires, 23 % ont déjà été mariés et 21 % sont actuellement mariés.
Dans cet article, nous avons exploré les fondamentaux de la statistique descriptive en se penchant sur la description des variables. Cependant, la statistique descriptive ne s’arrête pas là. Elle sert de base à de nombreuses autres analyses statistiques, y compris la statistique descriptive bivariée que nous aborderons dans un prochain article.
Si cet article vous a plu et que vous souhaitez continuer à explorer le passionnant monde de la data, nous vous encourageons vivement à vous abonner à notre blog. De plus, nous sommes toujours ravis d’entendre vos commentaires et vos questions. Si vous avez des interrogations spécifiques, des sujets que vous aimeriez voir abordés en détail ou simplement des réflexions à partager, n’hésitez pas à laisser un commentaire sous cet article.