Indicateurs pour Mesurer la Relation entre deux Variables quantitatives
tutoriel
Rstudio
Datamangement
Statistique
Published
August 2, 2024
Que l’on souhaite identifier des corrélations, sélectionner les variables les plus pertinentes pour un modèle ou simplement explorer nos données, la compréhension des liens entre les variables est essentielle en analyse de données. Cette démarche permet non seulement d’identifier les variables corrélées, mais aussi de déterminer quel type de modèle est le plus approprié pour les données à disposition. Par exemple, comprendre les corrélations entre variables peut aider à choisir des techniques de modélisation plus adaptées et à éviter des problèmes tels que la multicolinéarité.
En effet, de nombreux modèles statistiques et algorithmes de machine learning peuvent être perturbés par une forte multicolinéarité, où les variables explicatives sont trop corrélées entre elles. Cela peut entraîner des estimations instables et une interprétation erronée des résultats. En analysant correctement les relations entre les variables, on peut également décider s’il est nécessaire de transformer les données ou d’appliquer des méthodes spécifiques pour réduire les dépendances indésirables.
Voici les indicateurs les plus couramment utilisés pour quantifier la relation entre deux variables quantitatives. Si vous souhaitez faire une analyse bivariée entre variables qualitatives n’hésitez pas à consulter notre article dédié à ce sujet. Vous trouverez aussi ici des informations précieuses pour la statistique descriptive.
Coefficient de corrélation de Pearson
Le coefficient de corrélation de Pearson est sans doute l’indicateur le plus connu pour mesurer la force et la direction d’une relation linéaire entre deux variables continues. Il varie de -1 à 1, où -1 indique une corrélation négative parfaite, 0 une absence de corrélation linéaire et 1 une corrélation positive parfaite. Bien qu’il soit facile à interpréter et largement utilisé, il présente certaines limites : il ne détecte que les relations linéaires et est sensible aux valeurs extrêmes.
Coefficient de corrélation de Spearman
Lorsque les relations ne sont pas nécessairement linéaires, le coefficient de corrélation de Spearman offre une alternative intéressante. Basé sur les rangs des valeurs plutôt que sur les valeurs elles-mêmes, il mesure la force d’une relation monotone. Il est moins sensible aux valeurs extrêmes que Pearson, mais perd de l’information en travaillant sur les rangs.
Coefficient de corrélation non linéairec Xi
Les coefficients de corrélation classiques,Pearson ou Spearman, peuvent ne pas être adaptés dans certaines situations. C’est le cas par exemple lorsque relation n’est ni linéaire ni monotone. Une alternative efficace est le coefficient de corrélation non linéairec Xi. Ce coefficient est basé sur la corrélation entre les rangs des incréments des variables et permet de capturer la dépendance structurelle entre les variables, sans faire d’hypothèses strictes sur la forme de cette relation. Vous pourez en apprendre plus dessus dans cet article
Application
Comment utiliser R pour calculer ces principaux indicateurs. Nous allons utiliser des données synthétiques pour illustrer ces notions
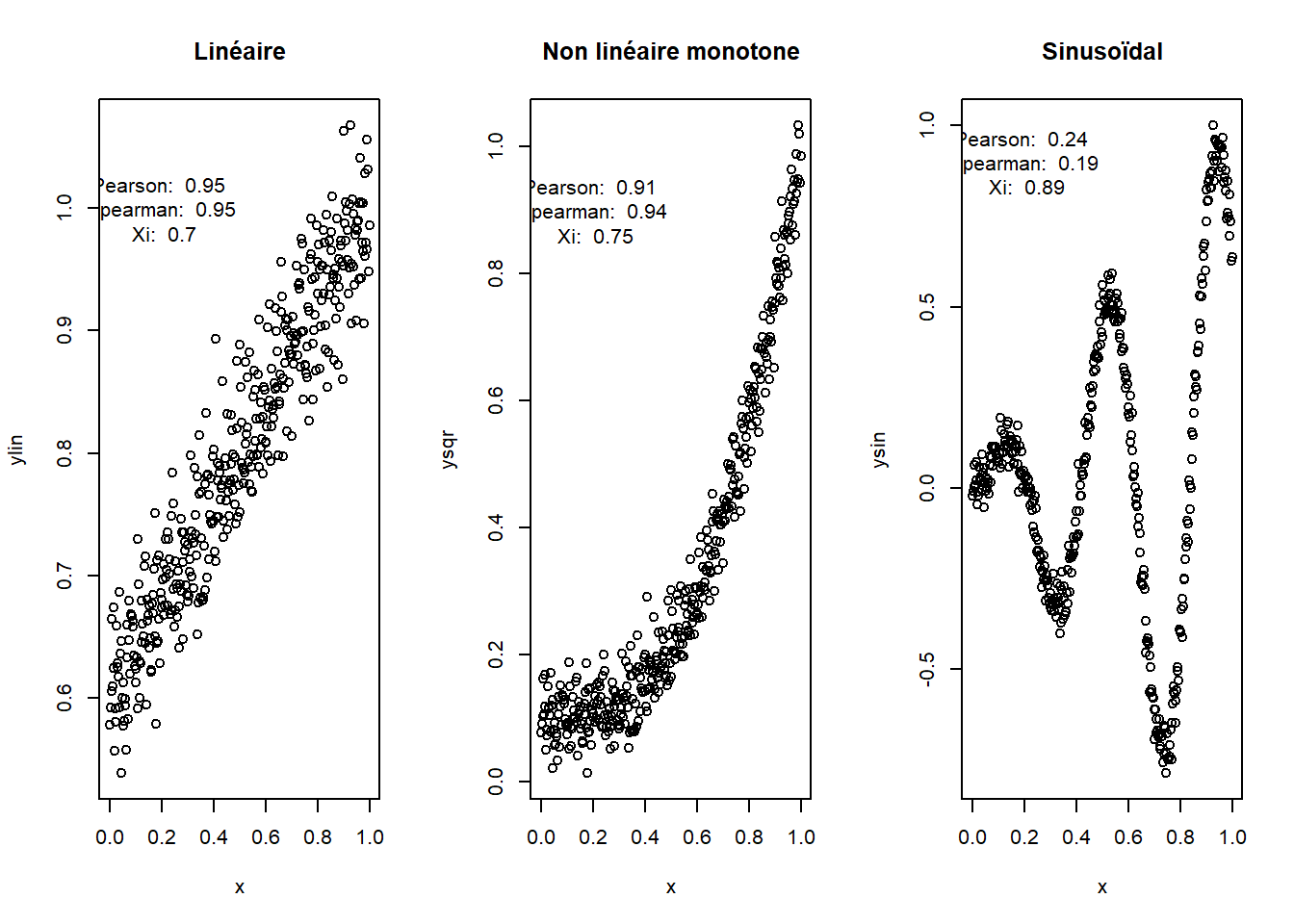
library(XICOR) # Package contenant la fonction de calcul du Xiset.seed(123) # Pour rendre le travail reproductible# Fonctions pour générer des donnéessignalLin <-function(x) 0.4* x +0.6# Fonction linéairesignalSqu <-function(x) 0.9* x^3+0.1# Fonction non linéaire monotonesignalSin <-function(x) x *sin(15* x)# Fonction sinusoïdalen =400# Nombre d'échantillonsdbruit =0.04# Ecart type du bruit # Génération du bruitbruit =rnorm(n, mean =0, sd = sdbruit) # X x =seq(from =0, to =1, length = n)## Génération des valeurs à l'aide des fonctions + du bruitylin =signalLin(seq(from =0, to =1, length = n)) + bruit # Y linéaireysqr =signalSqu(seq(from =0, to =1, length = n)) + bruit # Y non linéaire, monotoneysin =signalSin(seq(from =0, to =1, length = n)) + bruit # Y sinusoïdal# Visualisation par(mfrow =c(1, 3)) # pour créer 3 graphiques sur la meme ligneplot(x, ylin, main ="Linéaire")text(0.2, 1, paste( "Pearson: ", round(cor(x, ylin),2) , "\n","Spearman: ", round(cor(x, ylin, method ="spearman"),2), "\n","Xi: ", round(xicor(x, ylin),2) ))plot(x, ysqr, main ="Non linéaire monotone")text(0.2, 0.9, paste( "Pearson: ", round(cor(x, ysqr),2) , "\n","Spearman: ", round(cor(x, ysqr, method ="spearman"),2), "\n","Xi: ", round(xicor(x, ysqr),2) ))plot(x, ysin, main ="Sinusoïdal")text(0.2, 0.9, paste( "Pearson: ", round(cor(x, ysin),2) , "\n","Spearman: ", round(cor(x, ysin, method ="spearman"),2), "\n","Xi: ", round(xicor(x, ysin),2) ))
Les coefficients de corrélation calculés nous apportent des informations précieuses sur la nature des relations entre nos variables. Dans le cas linéaire, le coefficient de Pearson s’avère particulièrement efficace pour capturer la relation entre x et y, suggérant qu’un modèle linéaire serait adéquat pour ajuster nos données. Sa nature paramétrique lui confère une certaine robustesse par rapport au coefficient de Spearman. En revanche, le coefficient de Xi semble davantage sensible au bruit que nous avons introduit dans les données. Pour les relations non linéaires mais monotones, le coefficient de Spearman offre de meilleures performances, indiquant qu’un modèle linéaire simple pourrait ne pas suffire et qu’il serait judicieux d’envisager l’ajout de termes polynomiaux. Enfin, dans le cas d’une relation sinusoïdale (non linéaire et non monotone), le coefficient de Xi se distingue en révélant une dépendance entre x et y, là où les coefficients de Pearson et de Spearman tendent vers zéro. Ceci nous permet de conclure qu’un modèle linéaire ne s’ajusterait pas aux données
Cette observation souligne l’importance de considérer les meilleurs indicateurs pour rendre compte des relations entre différentes variables. Nous avons pu voir que l’utilisation des coefficients de corrélation de Pearson et Speaman ne suffisent pas toujours à capturer une relation entre les variable. Des valeurs proches de 0 de ces coéficients indiquent juste une absence de relation linéaire et/ou monotone.