Fondements Mathématiques Essentiels en Data Science
Pour exceller en data science, particulièrement dans le domaine de la santé, il est indispensable de posséder une solide formation en mathématiques. Cette formation englobe la maîtrise de l’algèbre linéaire, de l’analyse mathématique, de la statistique et des probabilités. En outre, être à l’aise avec la programmation et les outils informatiques est crucial pour mener à bien des projets data.
L’Algèbre Linéaire
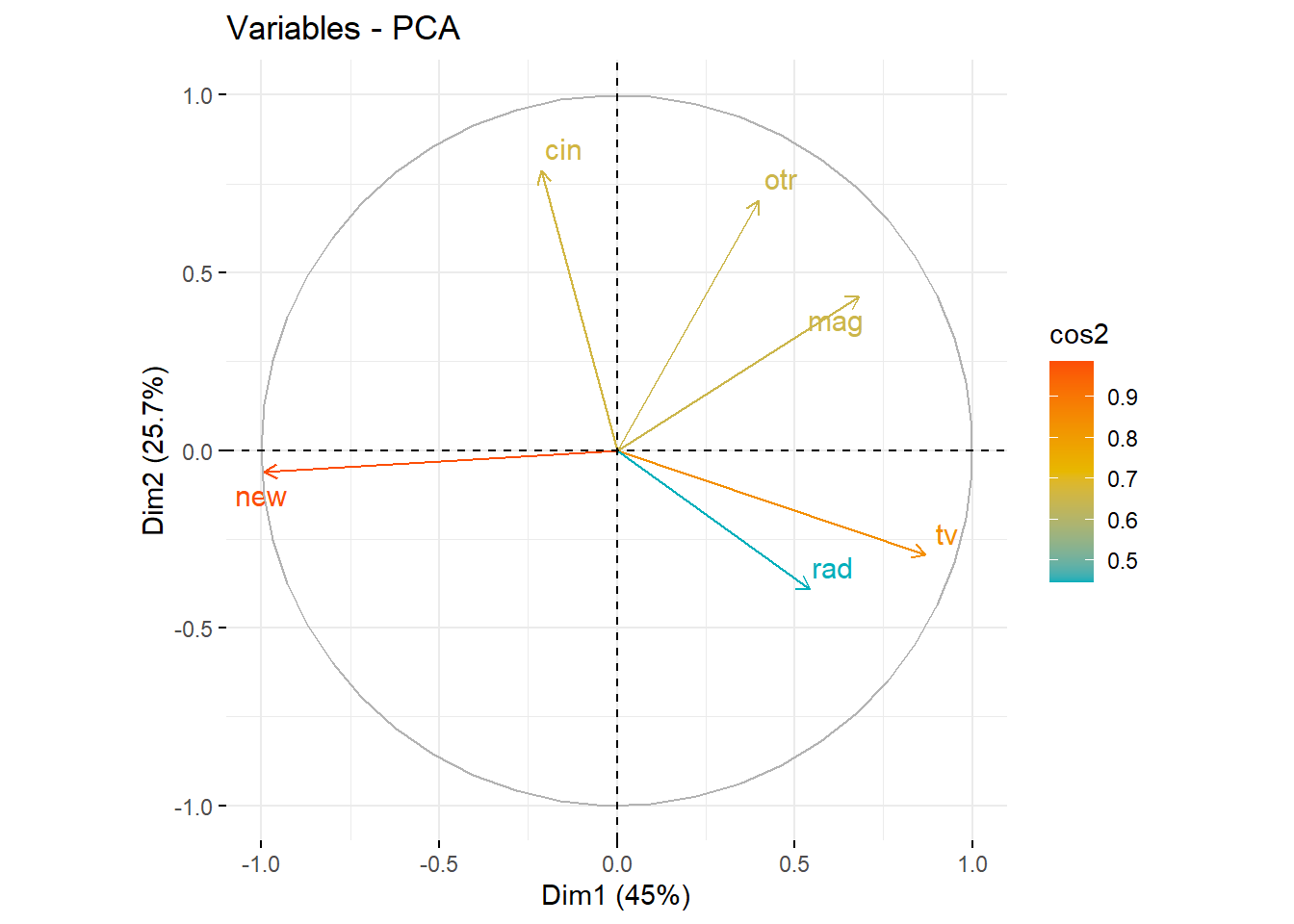
L’algèbre linéaire est au cœur de nombreuses techniques de data science. Les concepts de vecteurs, matrices, équations linéaires et géométrie analytique sont fondamentaux pour comprendre et manipuler les données. Les vecteurs servent souvent à représenter les caractéristiques d’un échantillon de données, tandis que les matrices, omniprésentes dans les calculs du Machine Learning, peuvent être vues comme des ensembles de vecteurs. Les équations linéaires permettent de modéliser de nombreux problèmes de façon systématique, et leur résolution fait appel aux techniques de l’algèbre linéaire. La géométrie analytique, utilisant des coordonnées pour représenter des formes géométriques, est cruciale pour calculer des distances entre points de données, ce qui est essentiel dans de nombreux algorithmes.
Pour illustrer, pensez aux matrices comme à des tableaux de nombres organisés en lignes et en colonnes. Ces tableaux peuvent représenter diverses données, allant de simples statistiques à des images complexes. Par exemple, une image numérique est essentiellement une matrice où chaque élément du tableau correspond à un pixel de l’image, avec des valeurs indiquant les couleurs ou les niveaux de gris. Une solide compréhension de l’algèbre linéaire est donc indispensable pour développer et appliquer efficacement des modèles en data science.
L’Analyse Mathématique
L’analyse mathématique se concentre sur l’étude des changements continus, contrairement à la géométrie qui traite des formes et l’algèbre qui généralise les opérations arithmétiques. Les concepts clés incluent la dérivation et l’intégration, cruciaux pour les algorithmes de machine learning qui reposent souvent sur des problèmes d’optimisation. Le calcul différentiel est particulièrement important car les dérivées permettent d’identifier les points critiques en optimisation, via des outils comme les dérivées partielles et les gradients. Le calcul intégral, quant à lui, est employé dans les méthodes probabilistes pour traiter des variables continues, transformant des sommes discrètes en intégrales. Bien que les notions d’analyse requises en data science soient limitées, une bonne compréhension des concepts fondamentaux est indispensable.
Probabilités et Statistiques
Les probabilités et la statistique sont essentielles pour modéliser l’incertitude et prendre des décisions basées sur les données. Les concepts de variables aléatoires, de distributions de probabilité (comme la loi normale, la loi binomiale et la loi de Poisson) et la probabilité conditionnelle sont essentiels pour comprendre les processus stochastiques et pour l’inférence statistique. La théorie des probabilités fournit les outils nécessaires pour estimer les paramètres des modèles à partir des données échantillonnées. Les notions d’espérance, de variance et de covariance sont cruciales pour analyser la distribution des données et la relation entre les variables. Les tests d’hypothèses, les intervalles de confiance et les analyses de régression permettent d’interpréter les résultats et de tirer des conclusions significatives des données.